Understanding Git Internals
How does git clone really work?
Before starting, I assume you are familiar with git. If you know about commits, branches, remote, cloning, staging and committing, you should be fine. Let’s build upon that.
Section 1: Git Storage Model
If you are familiar with the git’s object-based storage model, you can skip this section.
Git stores the entire snapshot of your project each time you commit. This is made possible by its object-based storage model. Here are some terms you should know.
- Objects: Everything Git stores is an object. Each object is uniquely identified by a SHA-1 (or SHA-256) hash and stored in the
.git/objectsdirectory. - Blob (Binary Large Object): A blob stores the contents of a single file. It does not store the filename—just the file’s content.
- Tree: A tree represents a directory. It contains pointers to blobs (files) and other trees (subdirectories), along with names and metadata like file permissions.
- Commit: A commit points to a tree and contains metadata like the author, timestamp, message, and parent commit(s). It represents a snapshot of the project at a given point in time.
When you commit a change, git does the following:
- Blobs are created for the contents of each file in the project.
- A tree object is created to map the directory structure and link to those blobs.
- A commit object is created pointing to the tree, along with a reference to its parent commit (if any).
- A ref (e.g.,
mainorHEAD) is updated to point to the new commit hash.
All these objects are saved in the .git/objects/ directory, compressed using zlib and named after their hash values.
It is relatively easy to follow how git does so. Do the following
# Make a repo
mkdir your-repo
cd your-repo
# create some files
echo "first file" >> foo.txt
mkdir bar
echo "second file" >> bar/baz.txt
# add and commit
git add .
git status
git commit -m "first commit"
Use git log to find the hash of current commit.
commit 53b1b80d093d7ad66a3f612a56e0215ad9da5952 (HEAD -> main)
Author: Udeshya Dhungana <udeshyadhungana1@gmail.com>
Date: Mon May 19 14:34:36 2025 +0545
first commit
Let’s observe our commit object inside the .git/objects directory using
python -c "import zlib,sys;print(zlib.decompress(open(sys.argv[1],'rb').read()).decode())" .git/objects/53/b1b80d093d7ad66a3f612a56e0215ad9da5952
Make sure to insert a slash after the first two characters of the SHA1 hash. It is how git stores them. We are using zlib to decompress the object file and read its contents because Git stores object using the zlib compression. The name of the commit (or the sha1 sum) is the sha1 sum of all the contents inside the commit object (including headers).
commit 203tree 377295adbf4e9f01892fd377e467549b38adc16b
author Udeshya Dhungana <udeshyadhungana1@gmail.com> 1747644576 +0545
committer Udeshya Dhungana <udeshyadhungana1@gmail.com> 1747644576 +0545
first commit
You can read this, but let’s see what’s going on by passing it through hexdump.
00000000 63 6f 6d 6d 69 74 20 32 30 33 00 74 72 65 65 20 |commit 203.tree |
00000010 33 37 37 32 39 35 61 64 62 66 34 65 39 66 30 31 |377295adbf4e9f01|
00000020 38 39 32 66 64 33 37 37 65 34 36 37 35 34 39 62 |892fd377e467549b|
00000030 33 38 61 64 63 31 36 62 0a 61 75 74 68 6f 72 20 |38adc16b.author |
00000040 55 64 65 73 68 79 61 20 44 68 75 6e 67 61 6e 61 |Udeshya Dhungana|
00000050 20 3c 75 64 65 73 68 79 61 64 68 75 6e 67 61 6e | <udeshyadhungan|
00000060 61 31 40 67 6d 61 69 6c 2e 63 6f 6d 3e 20 31 37 |a1@gmail.com> 17|
00000070 34 37 36 34 34 35 37 36 20 2b 30 35 34 35 0a 63 |47644576 +0545.c|
00000080 6f 6d 6d 69 74 74 65 72 20 55 64 65 73 68 79 61 |ommitter Udeshya|
00000090 20 44 68 75 6e 67 61 6e 61 20 3c 75 64 65 73 68 | Dhungana <udesh|
000000a0 79 61 64 68 75 6e 67 61 6e 61 31 40 67 6d 61 69 |yadhungana1@gmai|
000000b0 6c 2e 63 6f 6d 3e 20 31 37 34 37 36 34 34 35 37 |l.com> 174764457|
000000c0 36 20 2b 30 35 34 35 0a 0a 66 69 72 73 74 20 63 |6 +0545..first c|
000000d0 6f 6d 6d 69 74 0a 0a |ommit..|
000000d7
This shows that a commit object is stored like this:
commit<space><size_of_file_after_00>00<content>
The content is laid out as follows. Please note double newlines after committer line and the message line. If the commit has a parent tree, it is in between the author line and tree line.
tree<space><20_byes_of_sha1_pointing_the_tree_object>\n
author<space><author_name><space><mail_wrapped_in_angle brackets><space><time and timezone>\n
committer<space><committer name><space><mail wrapped in angles><space><time and timezone>\n\n
commit message\n\n
The SHA1 hash is the hash of the tree object (snapshot of the repo at the time of commit).
Let us see the details of that tree using git ls-tree sha1
040000 tree 5b927967da7802a015477771744c25136ff6df61 bar
100644 blob 303ff981c488b812b6215f7db7920dedb3b59d9a foo.txt
This indicates that at the time of commit, there was a file named foo.txt and a directory bar. To see what is inside bar, let us use ls-tree on the sha1 hash of the bar directory.
100644 blob 1c59427adc4b205a270d8f810310394962e79a8b baz.txt
It reveals that the bar directory at the time of commit had a baz.txt inside it. To view the contents of the files, use git cat-file -p command on the sha1 of the files
$ git cat-file -p 303ff981c488b812b6215f7db7920dedb3b59d9a
first file
For the second one,
$ git cat-file -p 1c59427adc4b205a270d8f810310394962e79a8b
second file
Let us inspect the tree file now. As before, do this:
python -c "import zlib; print(zlib.decompress(open('.git/objects/37/7295adbf4e9f01892fd377e467549b38adc16b', 'rb').read()))"
You will see sth like this
python -c "import zlib; import sys; sys.stdout.buffer.write(zlib.decompress(open(sys.argv[1], 'rb').read()))" .git/objects/37/7295adbf4e9f01892fd377e467549b38adc16b | hexdump -C
00000000 74 72 65 65 20 36 35 00 34 30 30 30 30 20 62 61 |tree 65.40000 ba|
00000010 72 00 5b 92 79 67 da 78 02 a0 15 47 77 71 74 4c |r.[.yg.x...GwqtL|
00000020 25 13 6f f6 df 61 31 30 30 36 34 34 20 66 6f 6f |%.o..a100644 foo|
00000030 2e 74 78 74 00 30 3f f9 81 c4 88 b8 12 b6 21 5f |.txt.0?.......!_|
00000040 7d b7 92 0d ed b3 b5 9d 9a |}........|
00000049
A tree object is laid out as follows:
tree<space><size_after_null_terminator>00
<mode><space><name>00<20_bytes_sha1>
<mode><space><name>00<20_bytes_sha1>
The mode refers to the permissions of the file/directory. Git does not store all of the UNIX permissions. Here are all the modes you will encounter in git.
| Mode | Type | Description |
|---|---|---|
100644 | blob | Normal file (non-executable) |
100755 | blob | Executable file |
120000 | blob | Symbolic link |
160000 | commit | Git submodule (pointer to a commit) |
40000 | tree | Directory |
Let us also observe the blob files.
python -c "import zlib; import sys; sys.stdout.buffer.write(zlib.decompress(open(sys.argv[1], 'rb').read()))" .git/objects/30/3ff981c488b812b6215f7db7920dedb3b59d9a | hexdump -C
python -c "import zlib; import sys; sys.stdout.buffer.write(zlib.decompress(open(sys.argv[1], 'rb').read()))" .git/objects/1c/59427adc4b205a270d8f810310394962e79a8b | hexdump -C
Here are their outputs
First File
00000000 62 6c 6f 62 20 31 31 00 66 69 72 73 74 20 66 69 |blob 11.first fi|
00000010 6c 65 0a |le.|
00000013
Second File
00000000 62 6c 6f 62 20 31 32 00 73 65 63 6f 6e 64 20 66 |blob 12.second f|
00000010 69 6c 65 0a |ile.|
00000014
Here, we can conclude that the structure of a blob object is as follows:
blob<space><size_after_null_terminator>00<content>
So, in summary, when you commit, a commit object is created which holds the sha1 sum of a tree object. The tree object’s contains the sha1 sum of files and directories present in the root directory of your project. By following these hashes, you will get to the sub-directories and all the files that was present at the time of the commit.
That is all you need to know about the git’s object based storage model.
Section 2: Git Clone
Git clone is done by making a request from a git client (installed on your system) to a git server (e.g. GitHub, Gitlab, or your own git server). Git uses either SSH or HTTP(S) to communicate with the server. You will find the protocol referred to as Smart HTTP(s) because there’s a special syntax to that.
Git clone takes place in two steps.
Ref Discovery
- The client asks the server what refs are available.
- The server sends a list of refs that are available and a list of capabilities.
Refs are just human-readable pointers to commits. Capabilities are features that the git server supports. For example, side-band means if you make the next request (about which I will talk about soon), the server will also send the progress alongside pack files. There are other features about which you can find more here: https://git-scm.com/docs/protocol-capabilities.
I have implemented my own git using Codecrafter’s Build Your Own Git challenge, which I will use to show the details the cloning process. You can find the code here.
Let us make the ref-discovery request first.
/* ...... code ...... */
func GetGitUploadPack(repoURL string) (*http.Response, error) {
serviceURL := fmt.Sprintf("%s/info/refs?service=git-upload-pack", repoURL)
return http.Get(serviceURL)
}
/* ...... code ...... */
The structure of response is as follows
001e# service=git-upload-pack
0000
015547b37f1a82bfe85f6d8df52b6258b75e4343b7fd HEADmulti_ack thin-pack side-band side-band-64k ofs-delta shallow deepen-since deepen-not deepen-relative no-progress include-tag multi_ack_detailed allow-tip-sha1-in-want allow-reachable-sha1-in-want no-done symref=HEAD:refs/heads/master filter object-format=sha1 agent=git/github-203a3d8c358f
003f47b37f1a82bfe85f6d8df52b6258b75e4343b7fd refs/heads/master
0000
Git PKT Line Format
To understand this better, git uses a PKT line encoding. Each line starts with 4 hex digits, which indicates the size of the line, including itself and trailing newline. A special flush line has just 0000.
For example, see the line starting with 0155.
015547b37f1a82bfe85f6d8df52b6258b75e4343b7fd HEADmulti_ack thin-pack side-band side-band-64k ofs-delta shallow deepen-since deepen-not deepen-relative no-progress include-tag multi_ack_detailed allow-tip-sha1-in-want allow-reachable-sha1-in-want no-done symref=HEAD:refs/heads/master filter object-format=sha1 agent=git/github-203a3d8c358f
The 0155 part indicates that the line is 341(0x155) bytes long. You can check for it yourself.
Lines starting with # are comments and can be ignored. However, git protocol specifies that the server must respond with # service=git-upload-pack on the first line.
For the lines that are not comment or flush, they are structured as follow
<4 bytes for size><20 bytes for shasum><space><ref_name>\n
Please keep in mind that I haven’t touched upon the lines that contain information on tags.
Only the first line contains capabilities, and is structured as follows:
<4 bytes for size><20 bytes for shasum><space><ref_name>00<capabilities separated by space>\n
From here, grab the shasum of the HEAD and proceed to making upload-pack request. You may also include other commits, but let’s see an example with a single one. It will be enough to understand the rest.
Upload Pack POST
func PostGitUploadPack(repoURL, want string) (*http.Response, error) {
var body bytes.Buffer
body.Write(pktLine(fmt.Sprintf("want %s\n", want)))
body.Write(flushPkt())
body.Write(pktLine("done\n"))
req, err := http.NewRequest("POST", repoURL+"/git-upload-pack", &body)
if err != nil {
return nil, err
}
req.Header.Set("Content-Type", "application/x-git-upload-pack-request")
req.Header.Set("Accept", "application/x-git-upload-pack-result")
return http.DefaultClient.Do(req)
}
Here, want is the sha1sum of the HEAD that you grabbed from the previous request. Right now, I am not requesting the server for any capabilities to show you the bare-minimum implementation of git clone.
The response to this request is a git pack file. Let me show you the structure of a packfile.
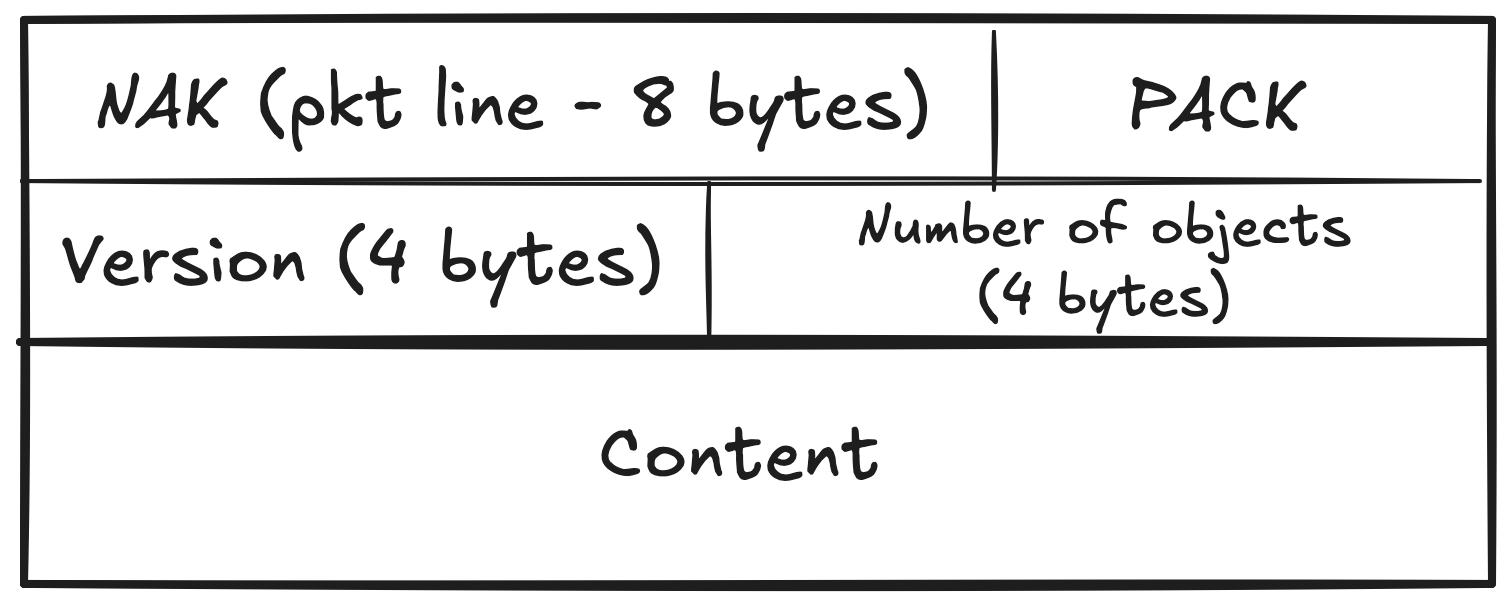
A packfile starts with a pkt-line encoded “NAK” literal. It is followed by a literal “PACK” literal.
Packfile Header
The next 4 bytes after that is designated for the version and the next 4 bytes after that correspond to the number of objects in the body that follows.
There is an important point to note here. The version and number of objects are stored in big-endian format. If you are familiar with big-endian and little-endian formats, you can skip this part. For the ones who aren’t, please continue reading.
Let us decode one to understand. Suppose, we encounter 00 00 00 02 while reading version and 00 00 01 4c while reading the number of objects field.
In big endian format, the most significant byte comes first. So,
Bytes (hex): 00 00 00 02
Position: MSB LSB
This means that the version is 2.
Bytes (hex): 00 00 01 4c
Position: MSB LSB
This equates to 332 (0x0000014c) in decimal.
So, there are 332 unique objects that we will encounter next.
Packfile Body
Now, let us see how the contents of the packfile body is organized.
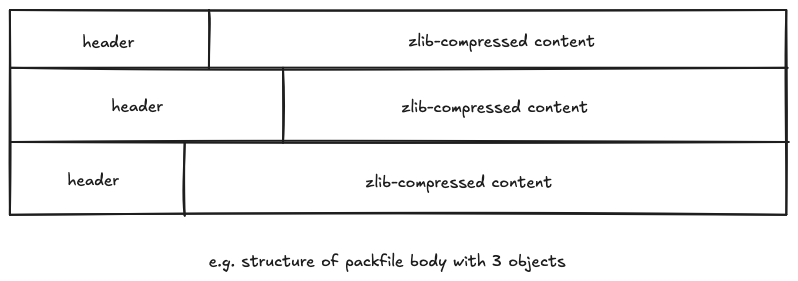
The illustration above shows that for each object, there will be a header section, and a zlib-compressed body section that will contain the object’s contents.
Object Header
The header section specifies two key things: object type, and the size of the object after decompression. The size is indicated so that the git client can allocate the memory for the decompressed object.
The object type may be any one of the following:
- COMMIT = 1 (001)
- TREE = 2 (010)
- BLOB = 3 (011)
- TAG = 4 (100)
- OFS_DELTA = 6 (110)
- REF_DELTA = 7 (111)
I will tell you what the numbers mean in a while.
Now, let us see how the object type and the object size can be extracted from the object header.
Read the first byte. The first byte’s bit[4-6] (index starts at 0) will tell you the type of the object. If you read the first byte into a variable b, you can find the size by doing following:
/* shift the byte to the right by 4 bits and AND with 0111, which will give you the object type */
objTypeCode := (b >> 4) & 0x7
The size is stored in a different way. Here is how you can extract it. From byte you just read (for extracting the type), just extract the 4 least significant bits.
/* extract the least significant 4 bits */
objectSize := int(b & 0x0F)
Now, Check for MSB of b.
- If it is 0, you are done.
- If not, read the next byte and extract the bits 0-6.
- Now, shift the byte you just read by 4 bits (remember that the byte you read before this has 4 bits), and OR it with
objectSize. - Check for MSB of the byte you just read, if it is 0, you are done.
- If not, read next byte, and again extract the bits 0-6.
- How much will you shift by this time? By 11 (7 + 4). By now, you must know what to do next.
- You only stop if the MSB of the byte you just read is 0. If not, you extract the bits 0-6, shift it to the left by appropriate amount, and OR it with the size variable.
objectSize = ....... | ....... | ....... | ....
byte3 byte2 byte1 byte0
The first 4 bits come from the first byte’s bits 0-3. The next 7 bits come from byte1 & 0x7F, the next 7 bits from byte2 & 0x7F and so on.
Now, if the object is of type REFDELTA, additional 20 bytes are reserved for the SHA1 sum of the object it references. I will explain what a REFDELTA is in a while. But for now, you will need to keep in mind that you need to extract the SHA1 sum as well, if the object type is refdelta.
I spent a few days trying to figure out why my zlib decompression was not working as I tried to decompress the content that was immediately available after objectSize for all types of objects, including REFDELTA
Object Body
The object body is a zlib compressed chunk of data. You will need to decompress using zlib first.
Now, if you observe the decompressed objects, you will notice that for blob, trees and commit, the content is a bit different from what it appears in the object file inside .git/objects directory. To be exact, the body only contains everything after null termination character if the object were to be stored in a git object file.
For example, for a blob, the content will not be
blob<space><size_after_null_terminator>00<content>
but rather, only
<content>
The same goes for tree and commit objects.
Now you can easily parse the contents of the object that appears in the packfile, except for the RefDeltas.
RefDelta
If you know a little bit of calculus, you might know that delta means a small change. So, what is a refdelta? Refdelta is an object, which contains a set of instructions to create a new object from an existing one.
But why refdeltas? Why can’t git send me entire objects instead of refdeltas?
Refdeltas offer an efficient way to store objects. It tracks only the changes to be made to an object to create a new one. For example, you have a 1000 line file that you committed. In the next commit, you added 10 new lines. It is not efficient to send you two different blobs. The git server will send you the first object and a refdelta that tracks only that change made to that object. In this case, the additional 10 lines.
Remember the 20 bytes SHA1 in the header section that I told you to keep track of while parsing the object header? Yes, that is the sha1 hash of the object it references.
How do I create a new object from RefDelta? That, I will tell you shortly. First, let us understand how a RefDelta object is structured.
How to extract the contents of RefDelta?
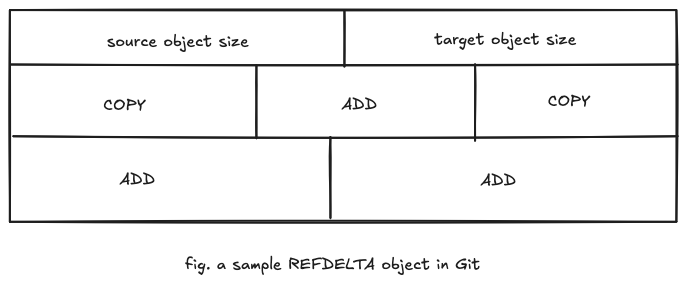
The Refdelta contains source object size, followed by the target object size. The source object size is the size of the object it references. The target size is the final size of the object that will be created after the ref-delta has been applied to the object it references. The target size is followed by a series of COPY and/or ADD instructions. I will explain this shortly. Let us first understand how the size encoding is done in refdelta.
How is source object size encoded?
The same way object size is encoded in packfile header. The only difference is that you start by extracting the LSB 0-6 of the first byte instead of LSB 0-3, and shift the next byte by 7 instead of 4 in the first iteration. Everything is exactly the same. You stop when the MSB of the byte you just read is 0. This is called LEB128 encoding.
For example let’s say you read these bytes (in hex):
0xE5 0x8E 0x26
Binary:
0xE5 = 11100101 → continuation bit set (more to read), value bits: 1100101 = 0x65
0x8E = 10001110 → continuation bit set, value bits: 0001110 = 0x0E
0x26 = 00100110 → last byte, value bits: 0100110 = 0x26
Decoding:
result = 0
result |= 0x65 << 0
result |= 0x0E << 7
result |= 0x26 << 14
Total = 100197
How is target object size encoded?
The same way as the source size is.
How are Instructions encoded?
A refdelta object will have two type of instructions: COPY and ADD.
- COPY: Copy data of size
nfrom offsetoffsetfrom the referenced file. - ADD: Insert these literal data to object.
After you’re done reading target object size, read next byte. If the MSB is 1, you are reading a COPY instruction. If it is 0, the instruction is ADD.
ADD
This one is very easy. Extract bits 0-6 from the byte you just read. It specifies the size of literal data in bytes. The literal data follows after this byte. You may have noticed that the maximum amount of data an ADD instruction can contain is 127 bytes (0x7F maximum). What if it git needs more than that? Git will simply insert a next ADD instruction after the first one if the size of literal data is greater than 127 bytes.
COPY
How do you extract data size (n) and the offset?
From the byte you just read,
- Bits 6-4: Contains information on data size
n. - Bits 3-0: Contains information on offset.
You must extract offset first, and then the size. Let me explain this using an example.
Let’s say the control byte b is:
b = 11101101
Let's break this down
bit 0 = 1 → read next byte (for offset) → used as bits 0–7 of offset
bit 1 = 0 → skip → if this was read, it would have been bits 8-15 of offset
bit 2 = 1 → read next byte (for offset) → used as bits 16–23 of offset
bit 3 = 1 → read next byte (for offset) → used as bits 24–31 of offset
bit 4 = 0 → skip
bit 5 = 1 → read next byte (for size) → used as bits 8–15 of size
bit 6 = 1 → read next byte (for size) → used as bits 16–23 of size
First you extract offset by iterating over each bit in the LSB.
If the bit is 1, read next byte and left shift it by 8 * i , where i is the position of current bit from the right, and OR it with offset. If it is 0, continue the loop.
Then you extract size by iterating over bits 4-6 of the control byte.
If it is 1, read next byte and left shift it by (i - 4) * 8 , where i is the position of the current bit from the right, and OR it with size. If it is 0, continue the loop.
Now, you should be able to parse the contents of RefDelta object.
Applying RefDelta
Even if you computed sha1 of all of the object you decompressed, none of the refdeltas’ referenced SHA will match any of them.
After extracting the non-delta objects, you should prepend their content with an appropriate header. For example, if you extracted a blob object, prepend it with
blob <size>00<content
Just like it would appear in a git object file, and then only compute its SHA1. Now, you might notice that at least one object’s SHA1 should match the refdelta’s referenced SHA.
Let’s see how a refdelta object is applied to an existing one to create a new one.
Let’s say we have a base file (original Git object):
Base file:
"Hello, my name is Alice.\n"
Given a refdelta object like this (The content on the right side of the arrow is the evaluation of that instruction)
COPY offset=0, size=18 → "Hello, my name is A"
ADD 3 bytes: "Bob" → replace "Alice" with "Bob"
COPY offset=23, size=1 → copy the "\n"
ADD 21 bytes: "Nice to meet you!\n"
After applying this to the base file, the new file will be
"Hello, my name is ABob\nNice to meet you!\n"
How to apply all deltas?
Store the delta objects in a queue. Keep dequeueing the queue until it is empty. On each dequeue, apply the refdelta to its referenced object. Generate a new object, and put it in your objects list.
After all deltas has been applied, initialize the .git directory, and save all the objects in .git/objects directory.
Populating the cloned directory
Keep track of the SHA1 of the HEAD. From there, find the sha1 of the head and it’s tree. Once you find the root tree, create every file and directory that appears in the tree object file, recursively. I am leaving this up to you. But this is how git does it.